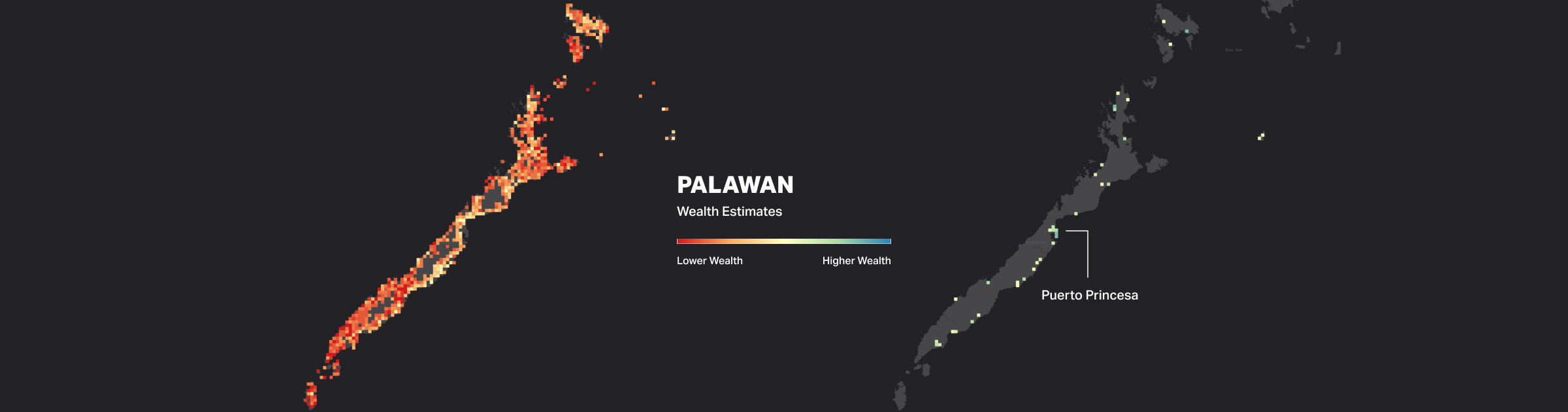
Mapping poverty in the Philippines with combined open geospatial datasets
In 2019, 20.8% of the Philippine population was estimated to be living below the poverty line. Several organizations and initiatives strive to reduce extreme poverty, but reaching zero extreme poverty by 2030 remains a major challenge. Locating vulnerable areas efficiently and effectively is critical for humanitarian organizations to formulate policies and plan interventions. To this end, many groups turn to surveys conducted by the Philippine Statistics Authority such as the APIS, FIES, or DHS for data on poverty.
While poverty surveys are fundamental to data collection, they are also expensive and infrequent. Surveys cover a random sample of the population, which can range in the tens of thousands of households. Collecting complete and up-to-date data for the entire country would require more large-scale and frequent surveys, which may be challenging for many organizations with limited resources.
To augment existing surveys, machine learning provides a scalable, reliable, and low-cost means to obtain information for areas that surveys do not cover. Previously, we developed a deep learning model based on the work of Jean et al., which uses high-resolution satellite images to estimate wealth at a granular level. While this performed well, the expense of purchasing and processing high-resolution images may still be a constraint for NGOs. Moreover, deep learning models are less explainable by nature, which is a drawback for non-technical decision makers who seek to understand what goes on under the hood.
Fortunately, more studies on poverty estimation methodologies have recently emerged which feature simple and novel techniques that yield similarly promising results. Here we adapt methods based on our previous work with the Qatar Computing Research Institute which utilizes Facebook data for wealth estimation, as well as novel studies from Zhao et al., Yeh et al., and Pokhriyal and Jacques that demonstrate the effectiveness of combining multiple geospatial datasets for predicting poverty in other developing countries.
Machine Learning with Open Geospatial Data
In our work, we use the 2017 Demographic and Health Survey as our source of ground truth. While the dataset is reliably sampled, it comes with caveats on spatial and temporal precision. To protect data privacy, the locations of households provided by the DHS program are offset by 2 to 5 kilometers. Since our ground truth values were collected in 2017, our features and wealth predictions are also adjusted for 2017 values. More recent values can only be rolled out when the next survey is conducted, which may be delayed due to the pandemic.
Our primary target of interest is the wealth index, a constructed wealth measurement based on assets ownership and resource access. Alongside this, we considered indicators that could measure other dimensions of vulnerability that would be of interest to development stakeholders. We derived values for water availability and access, toilet facility access, educational attainment, and out of school youth. Each vulnerability indicator was aggregated (by average or by proportion) for each of the 1200 household clusters. Here we present the indicator with the best performance: the wealth index.
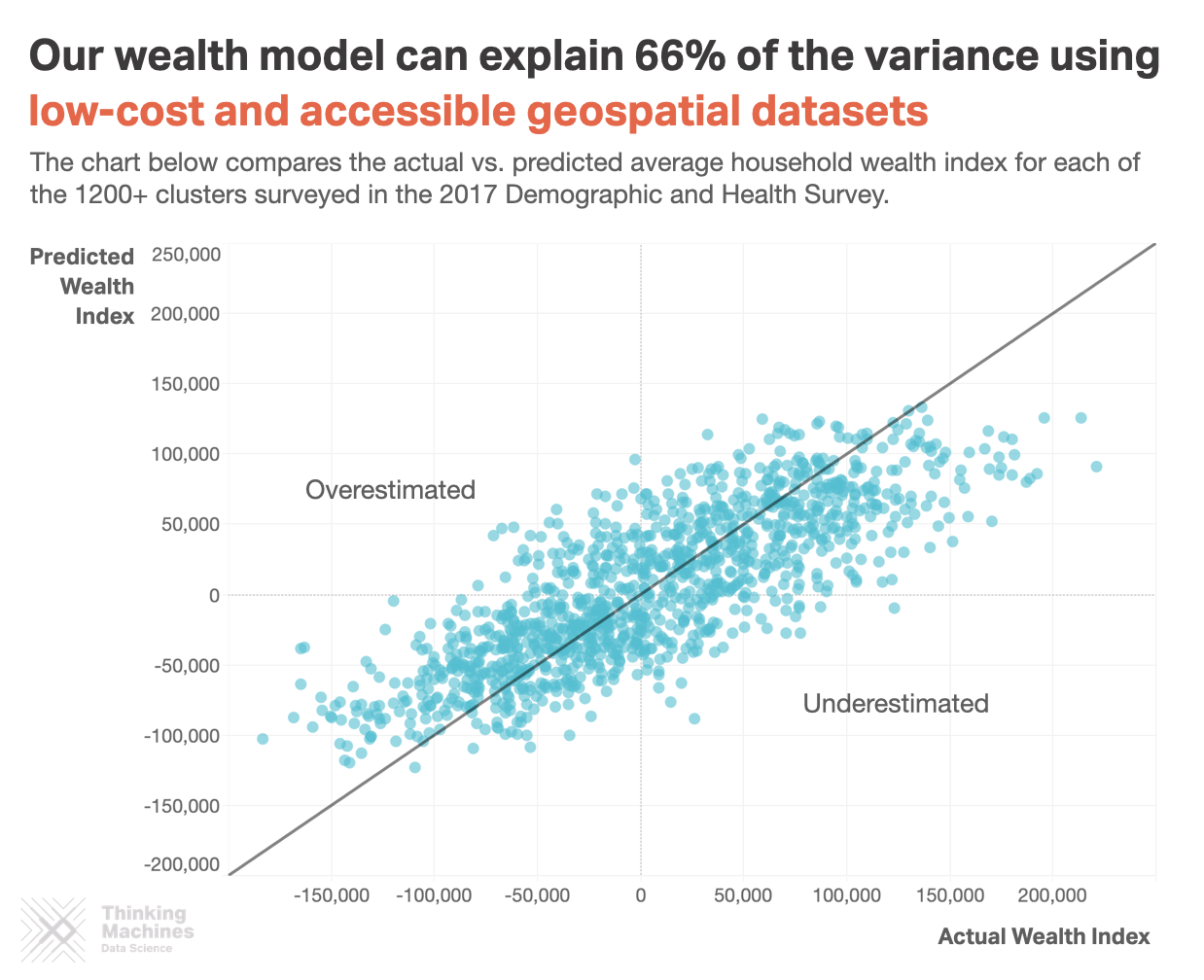
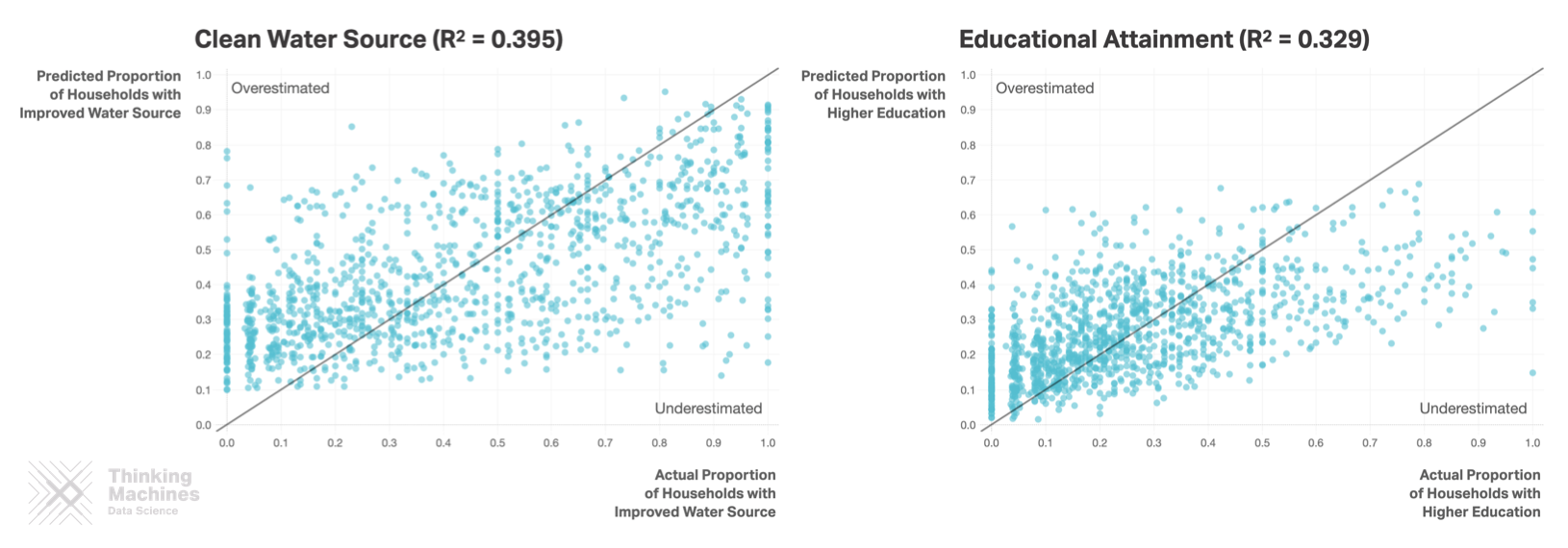
Accuracy per indicator. Other indicators did not yield promising results.
The novelty in our approach consists of combining several readily accessible geospatial datasets, which we aggregated per household cluster. The datasets include the following:
Facebook Advertising Data: We used Facebook’s Marketing API to extract information on the number of users with access to WiFi, 4G, 3G, 2G, and Apple devices, as well as those with consumer preferences for mid-to-high valued goods in each area. The data from Facebook is rounded up to the nearest 1000 (even if there are 0 users), so the number of users is not precise.
Remote Sensing Data: Using Google Earth Engine, we extracted information from publicly available, low-resolution satellite images including: (1) night time luminosity data taken from the Visible Infrared Imaging Radiometer Suite provided by NASA, (2) daytime and nighttime land surface temperature derived from MODIS Satellite 2017 data, and (3) Normalized Difference Vegetation Index (NDVI) derived from Landsat 2017. For each satellite image, we computed summary statistics, i.e. the mean, maximum, minimum, skewness, variance, and kurtosis, of all cloudless pixel values within each DHS cluster.
Points of Interest Data: Using OpenStreetMap (OSM), we obtained volunteered geographic information related to the counts of various points of interest, e.g. banks, restaurants, convenience stores, within each DHS household cluster. While OSM is known to be incomplete, using OSM POIs has resulted in well-performing models. We also accessed hospital data from the Department of Health’s National Health Facility Registry, as well as public school information from CheckMySchool, an education monitoring initiative in the Philippines. The latter dataset contains information on the number of students, teachers, classrooms, and students with disabilities as well as indicators for water, electricity, and internet access per school.
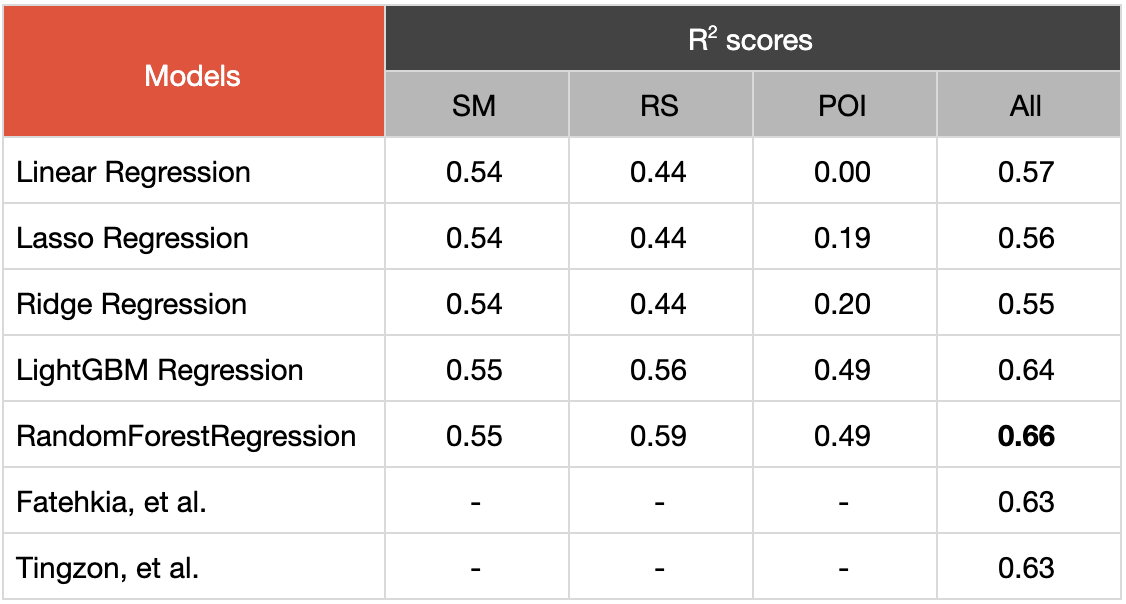
Experiment results. We predicted DHS wealth index using different feature sets: Social Media (Facebook), Remote Sensing, and Points of Interest. All models were evaluated with a 5-fold cross validation.
Based on our initial experiments, the Random Forest Regressor base model performed best among all the models across all feature sets. We selected the Random Forest Regressor for the next steps which included feature pruning and tuning our final model’s parameters. The resulting nationwide predictions are available at an 18 square kilometer granularity (around a tenth of the average municipality size) and can be visualized as a map.
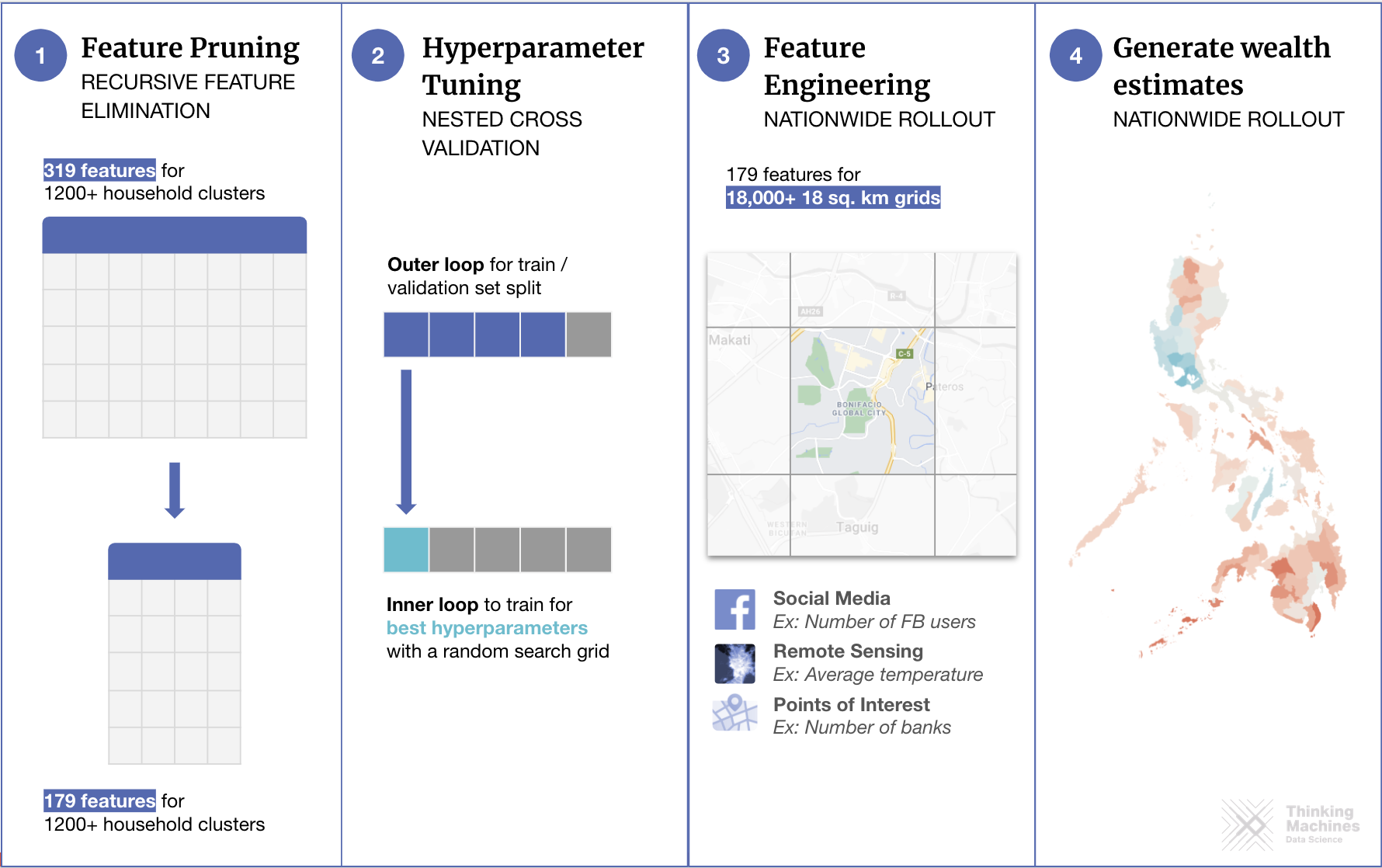
In addition to its predictive accuracy, another advantage of using the tree-based Random Forest model is its explainability. We explored two approaches to understand how the model estimates an area’s wealth under the hood.
A trained Random Forest model from sci-kit learn includes built-in calculation of feature importances used during model training. The feature importance quantifies the variance that a feature reduces. This explains how effectively a variable splits data into high and low wealth groups.
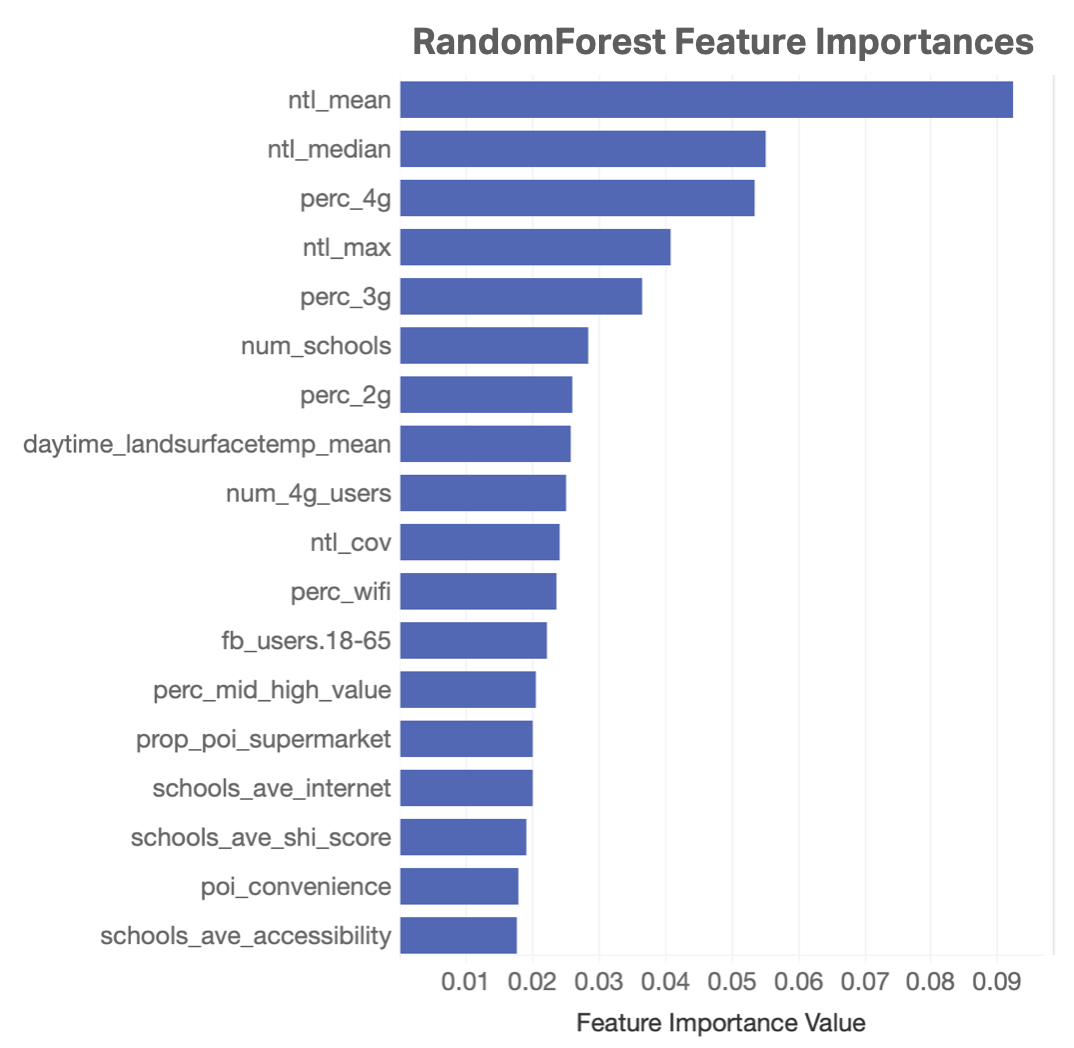
Wealth model’s feature importances. Based on Gini impurity, the most important features include the night time luminosity summary statistics, proportion of the population using 4G/3G/2G, and the number of schools.
Shapley Additive Explanations (SHAP) is a game theory-based approach to quantify the impact of each feature on a single prediction when that feature is added to the model.
For each feature, a SHAP value is computed as the average difference between model predictions when trained with and without the feature. This is computed by training the model on all subsets of variables, then taking the average difference between pairs of predictions – each containing a prediction generated on a subset of variables with the feature, and another on the same subset excluding it. SHAP provides both global and local interpretability, meaning we can quantify the variables which are important overall, and also see the specific contributions of all variables for each specific area.
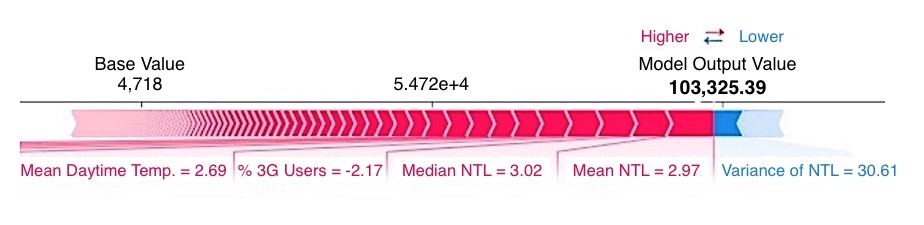
Local interpretability. SHAP values for a single observation. For this area deemed as wealthy, the nighttime luminosity and percentage of 3G user values increased the predicted wealth index above the average score of 4,718, while the covariance in its night time luminosity slightly decreased the wealth index.
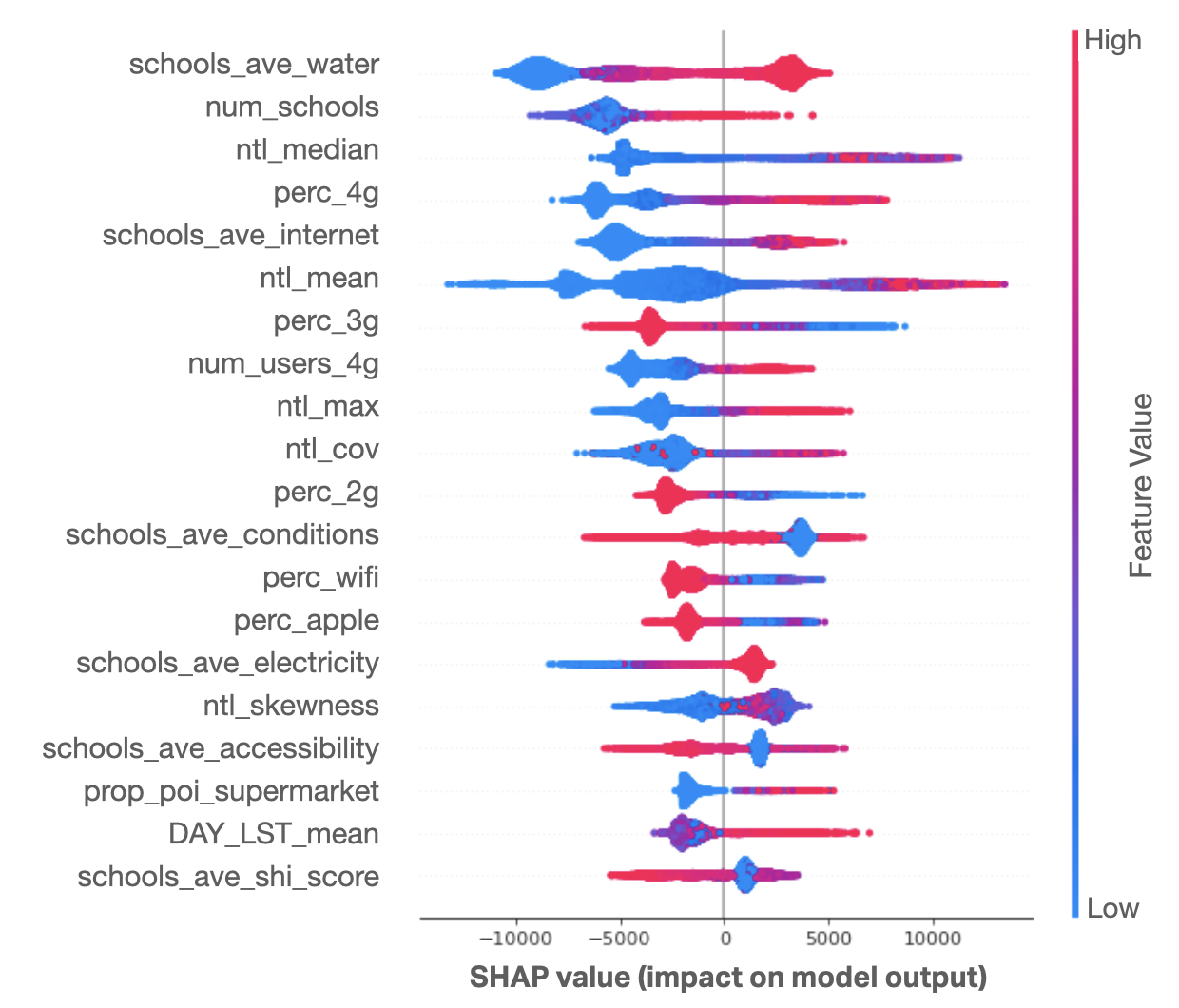
Global interpretability. SHAP values for all observations. Variables with wider spread have a wider range of impact on a prediction, such as night time luminosity mean and percent of 4G users. Variables with red values on the right and blue on the left positively correlate with wealth index (e.g. nighttime luminosity mean). When reversed, it indicates negative correlation (e.g. percent of 2G users).
The results agree with our understanding of the data. From Facebook data, higher percentages of 4G users indicate more wealth, as 4G data is more costly in the Philippines, while 2G and 3G are used more frequently in lower-wealth areas, which agrees with the negative correlations shown. Areas with higher proportions of supermarkets also tend to be wealthier, which is generally expected in urban areas. Finally, remote sensing data shows that areas with brighter lights and higher temperature are wealthier – typically characteristic of cities, as compared to rural areas.
What’s next?
Our work here has improved on previous Philippine benchmarks on poverty estimation, based on performance, accessibility, and interpretability. The low cost of this approach also allows for rapid iteration, which opens the door to future experiments with other datasets such as road networks, population density, and mobility. One interesting application we’ll be assessing is producing historical poverty estimates to study how the relationship between wealth and socioeconomic access has changed over time.
We presented this work at the NeurIPS 2020 Machine Learning for the Developing World workshop. We are honored to have been recognized as the workshop’s Best Paper, which is available here.
How can our team help you gain insights into location-based data? Leave us a message below and we’ll set up a conversation!


