OnTrackPH Technical Note
September 2016
At its core, OnTrackPH measures the statistical similarity between different texts – measuring the likelihood that several different government documents actually refer to the same project.
For our pilot test, we automatically generated a set of five potential matches for road projects across three massive national government databases spanning multiple years from 2013 to 2016:
- Line items in the Philippine National Budget General Appropriations Act (GAA)
- Procurement data in the Philippine Government Electronic Procurement System (PhilGEPS)
- Contracts in the DPWH Information Management System or Electronic Project Life-Cycle System (DPWH-EPLC).
The World Bank Philippines team of five analysts took three months to manually identify 2,238 matching records across the three databases. We used the 2,238 manually found records as an answer key, with the goal of automatically finding as many of the matches for those records as possible. The most recent iteration of OnTrackPH recommended the correct match for 85% of those records in under 15 minutes.
Given a list of 2,238 manually matched projects taken from the Farm-to-Market (FMR) list, OnTrackPH automatically found correct matches for 84.66% of them within the PhiLGEPS procurement data. OnTrackPH found 99% of the correct matches within the ePLC contract data.
Common Database Unification Challenges that OnTrackPH Addresses
There are several common data problems that any organization must address if they are looking to audit and reconcile information across data silos:
Data is spread over multiple databases with no clear interlinking keys. This was a problem we found in two of the databases we examined for our pilot test: public bids listed in PhilGEPS and contracts listed in DPWH-EPLC. There is a unique Reference ID for each project in PhilGEPS, and a unique Project ID in DPWH-EPLC, but no common ID that unambiguously links the two, making it extremely difficult to easily compare bids with the final contract.
Messy, inconsistently formatted names and descriptions. Names and project descriptions are not encoded consistently across databases, even if the information provided is accurate. This makes the analyst’s first tool, Control-F, almost useless for finding the right matches. For example, “Barangay Legaspi”, “Bgy. Legaspi”, and “Bgy. Legaspi North” might all refer to the same location.
A lack of standard names and categories. While every database contains some information about the government agency in charge of the project, every database logs that information differently. One might have the government department name in a distinct column, but another might combine department and agency into a single column. Names aren’t guaranteed to be standardized, which leads to situations where the Department of Energy is referred to as “DoE”, “Dept. of Energy”, and, “Department of Energy - Region I.”
Big datasets. The full PhilGEPS database is 53.68GB large and contains roughly 16 million records in total, of which there were 467,965 road procurement bids. The DPWH-EPLC has 64,547 road contracts, and 18 columns of information for each contract.
OnTrackPH tackles these problems in a reasonably fast and scalable way using methods of Natural Language Processing or NLP, a field within computer science that deals with training computer programs to understand human languages and respond to human users.
The OnTrackPH Matching Framework
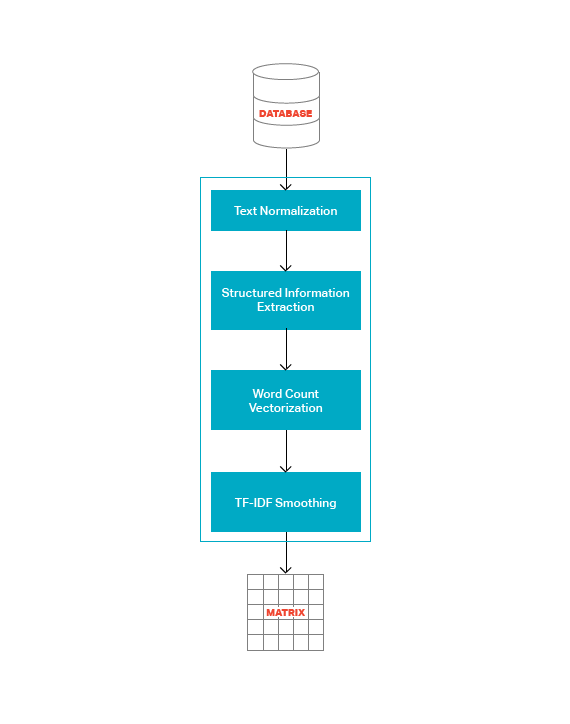
The OnTrackPH matching framework works in two parts. In the first part, as shown in Figure 1, OnTrackPH uses the following NLP methods to optimize the text for fast matching over big datasets. It normalizes the text, converts each row of information into a numerical word count vector, smoothes the vector, and combines the vectors into a large, sparse matrix that serves as a numerical representation of the initial text data. The specific steps are described in greater detail in the next section.
The subset of PhilGEPS data that was of interest to us contained 155,023 rows of text. After refining the data via the steps in Figure 1, we were left with a sparse matrix with 155,023 rows and 169,125 columns. This matrix contained 3,373,237 stored elements, which corresponds to the 1-gram and 2-gram word counts for each row.
We repeat this process for every database of interest, and should have one processed matrix per database.
Figure 1: Database to Matrix
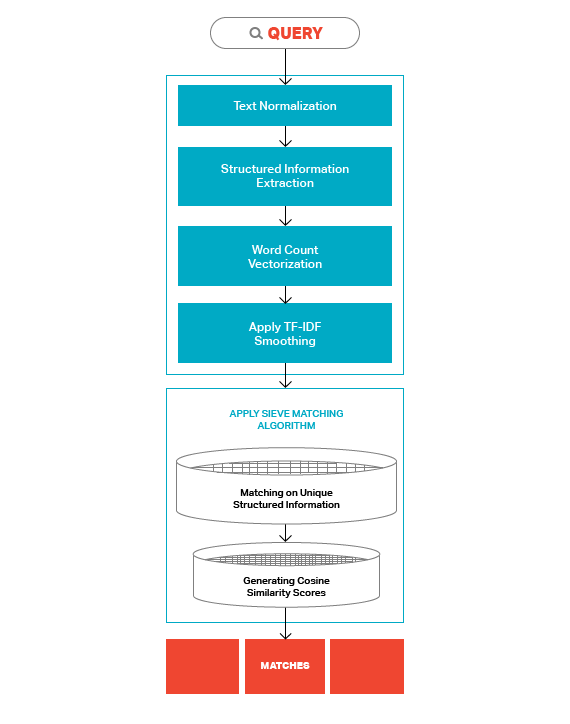
The second part of the OnTrackPH matching framework consists of the actual matching. Queries (text records for which we’re trying to find matches) go through the same set of NLP processing to generate an equivalent word vector, then we apply a sieve matching algorithm to the output.
The sieve matching algorithm works in two steps:
- First, it attempts to match the record based on any unique identifiers extracted. In our pilot test, contract ids extracted from the PhilGEPS description field allowed us to unambiguously match 524 records (~22% of our pilot dataset).
- If it can’t find any uniquely identifying matches, it generates a list of the best matches for our query based on how closely the query word vector matches with the document word vectors contained in the transformed database matrix.
Figure 2: Comparing a Query
Method Descriptions
- Text Handling and Normalization. By reducing the volume and complexity of text that will later be matched, normalization increases the algorithm’s speed and efficiency. All text is stripped down to its essential form, which involves converting characters to lowercase, stripping inconsequential punctuation, removing stop words or highly common words like “the” and “a”, and stemming or reducing words to their root forms.
- Structured Information Extraction. Analysts identify potentially uniquely identifying matches that are buried in bodies of text. In this particular pilot project, for example, the development team found that contract identification codes were present as a field in the EPLC, but buried in the description field of some of the PhilGEPS records. We used regular expressions to pattern match and extract these contract ids.
- Apply the Sieve Matching Algorithm. OnTrackPH takes a multi-step “sieve approach,” starting with finding the most precise matches before resorting to finding the more ambiguous matches. The layers of the sieve are as follows:

- Matching on Unique Structured Information. The algorithm scans each record for the uniquely identifying pieces of data identified by analysts in Step 2, and uses these to match records across different databases.
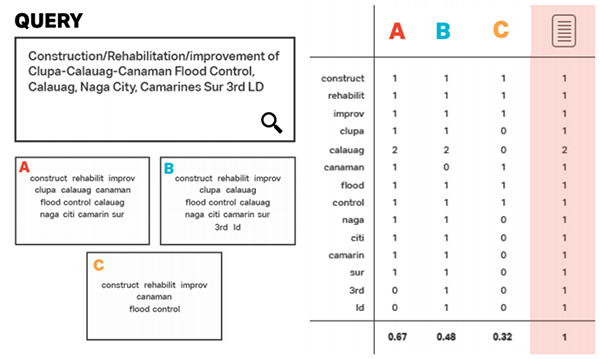
- Generating the word count vectors. The frequency of each unique word within a document is tallied, resulting in a matrix of word frequencies across all the documents in the corpus. During the pilot, we experimented with N-gram vectors for various values of N, and found that 2-gram vectorization gave us the best empirical results for matching.
- Applying Term Frequency-Inverse Document Frequency smoothing. The algorithm then calculates for each word in each document a metric called “Term Frequency - Inverse Document Frequency” or TF-IDF. TF-IDF is the frequency of a particular word in one document normalized by the frequency of that particular word across all the documents.The more important a particular word is to a particular document, the higher its TF-IDF score within that document. We used smoothing to add weight to uncommon words (which tended refer to specific place names) and removed weight from common words (which tended to be words about road infrastructure and construction).
- Generating cosine similarity scores. A method called “cosine matching” measures the similarity between two bodies of text via the number of uniquely identifying words they share. The more of these words that are shared by a budget line item, procurement bid, and contract, the greater the likelihood that these bodies of text refer to the same project. A query-candidate pair with a higher cosine similarity score are considered more likely to be a match, or to refer to the same real-world entity.
Strengths
The OnTrackPH framework works best in scenarios where every record has over five distinct words describing it. The more unique the descriptive words, the better the framework performs.
It’s algorithmically scalable up to millions of records. The initial pre-processing steps to generate the document matrix only needs to occur once. The vectorize and compare tasks can be parallelized, which means that framework can be ported over to any big data infrastructure (e.g. Apache Spark)
The concept and implementation of the word count vectorizer, TF-IDF, and cosine similarity matching are language-agnostic, or can be easily applied to any non-English body of text. Our pilot test dealt with data from the Philippines, which has both English and Filipino as national languages.
Limitations
The OnTrackPH framework performs poorly in situations where each individual record has fewer than five distinct words describing it.
The text normalization step relies on a dictionary of English-language stopwords and stemming rules, therefore this step will need significant reworking before it can be used in any other languages.
The OnTrackPH Code Library
We have made the OnTrackPH code library, a set of helper functions written in Python that can be used by any software developer for record linkage, available on Github as a piece of open source software under the MIT License.
References
- Nathanael Chambers and Dan Jurafsky Template-Based Information Extraction without the Templates (available here)
- Dan Jurafsky and James H. Martin (2008) Speech and Language Processing (2nd ed.)
