
Building a Twitter Big Data Pipeline with Python, Cassandra & Redis
Here at Thinking Machines, we are absolutely in love with data. We just can’t get enough of it. We’ve gotten traffic incident data, scraped online news articles, and partnered with data journalism organizations to get our hands on an extensive library of government records. And there are few things we love more than free, easily-accessible, and interesting data. Here’s where Twitter comes in.
Tweets! Tweets everywhere!
Data scientists love using social network data for predicting trends, conducting business intelligence studies, and doing complex network analysis, among other things. And with 645,750,000 registered users[1], Twitter’s data set is simply too good to ignore. (A lot of beginner data science courses start with gathering and analyzing Twitter data). Twitter generously provides a streaming API to allow access to public tweets. We can specify Twitter user IDs, certain search terms, or a geographic location as filters. In return, we receive a stream of tweets in easily parsable JSON. There are certain limits to using the API, but with the right combination of filters, we can end up with a ton of really cool data. But it’s probably not a good idea to stream gigabytes of data directly into your laptop.
Scalably handle big data storage with Cassandra
We would need a highly scalable, high capacity data store that can handle a large stream of data. PostgreSQL or MongoDB are are the usual solutions , but we wanted to road test a “big data” database, so we’re going with Cassandra. It’s a NoSQL, distributed database system designed to run in a cluster of servers. Because of its architecture, Cassandra provides high availability with no single point of failure. Also, once we get enough tweets to qualify as “big data”, Cassandra can be readily integrated with Hadoop and MapReduce. Cassandra is also low-latency, with very fast read/writes. This is important when you’re trying to build machine learning applications that need to respond in real time!
Setting it up as a single node cluster on Ubuntu as a proof of concept is pretty easy. We followed DataStax’s excellent guide on installing Cassandra on Ubuntu.
We first tried hosting it on a free tier t2.micro instance on Amazon EC2. That worked great for testing and development, but it’s definitely not for production environments. It was very unstable and crashed all the time, leading to some frustrating devops moments for our engineering team. The recommended minimum memory for a Cassandra node is 4GB, the more memory the better[2]. At 1GB of RAM, the t2.micro was clearly not up to scratch. Still, a good setup for a proof of concept.
For production, we used a Cassandra community AMI provided by DataStax, following their deployment guide. Aside from being much easier to set up, the AMI also includes DataStax OpsCenter which provides a nice web interface for managing the Cassandra cluster. We used an m3.large instance this time which has 7.5GB of memory, and the smallest instance type supported by the AMI.
Tweet Watching with Python & Redis
Now that we have our data store, we have to actually start collect tweets. Python is Thinking Machines’ favorite general purpose programming language. We love it! We use it for everything from web apps to data analysis. Python has a great community of people who work with it and a good collection of libraries for us to use. There’s no shortage of Twitter API clients written in Python, and most of them are great. We chose the python-twitter client for this project. It’s well documented and has pretty good test coverage. We set up a simple script to create a generator which yields each tweet as they come in.

The Twitter connection is a little tricky; it’ll drop if the receiving client fails to keep up with the data coming in from the stream. In order to make sure that our listener doesn’t fall behind, saving tweets to Cassandra is offloaded to a Redis Queue backed by Redis to be processed asynchronously.
After stabilizing our data pipeline and loading up on Tweets, our analysts started asking questions!
Querying with Cassandra—trickier than expected!
Cassandra’s Python driver has an object mapper reminiscent of Django’s ORM or SQLAlchemy. Anyone familiar with these tools would be right at home. It can also be used to create keyspaces, tables, fields and indices. We planned our data model based on the queries we intended to run. For example, we wanted to analyze user patterns, so we indexed the user field. We also wanted to look for specific words or phrases within a tweet, so we tried the following query:

Unfortunately, Cassandra’s text data type cannot be filtered with the CONTAINS keyword, in the same sense as a PostgreSQL database, for example. If you really need ad-hoc full text search, Cassandra easily integrates with Solr: a full text search open-source platform by Apache.
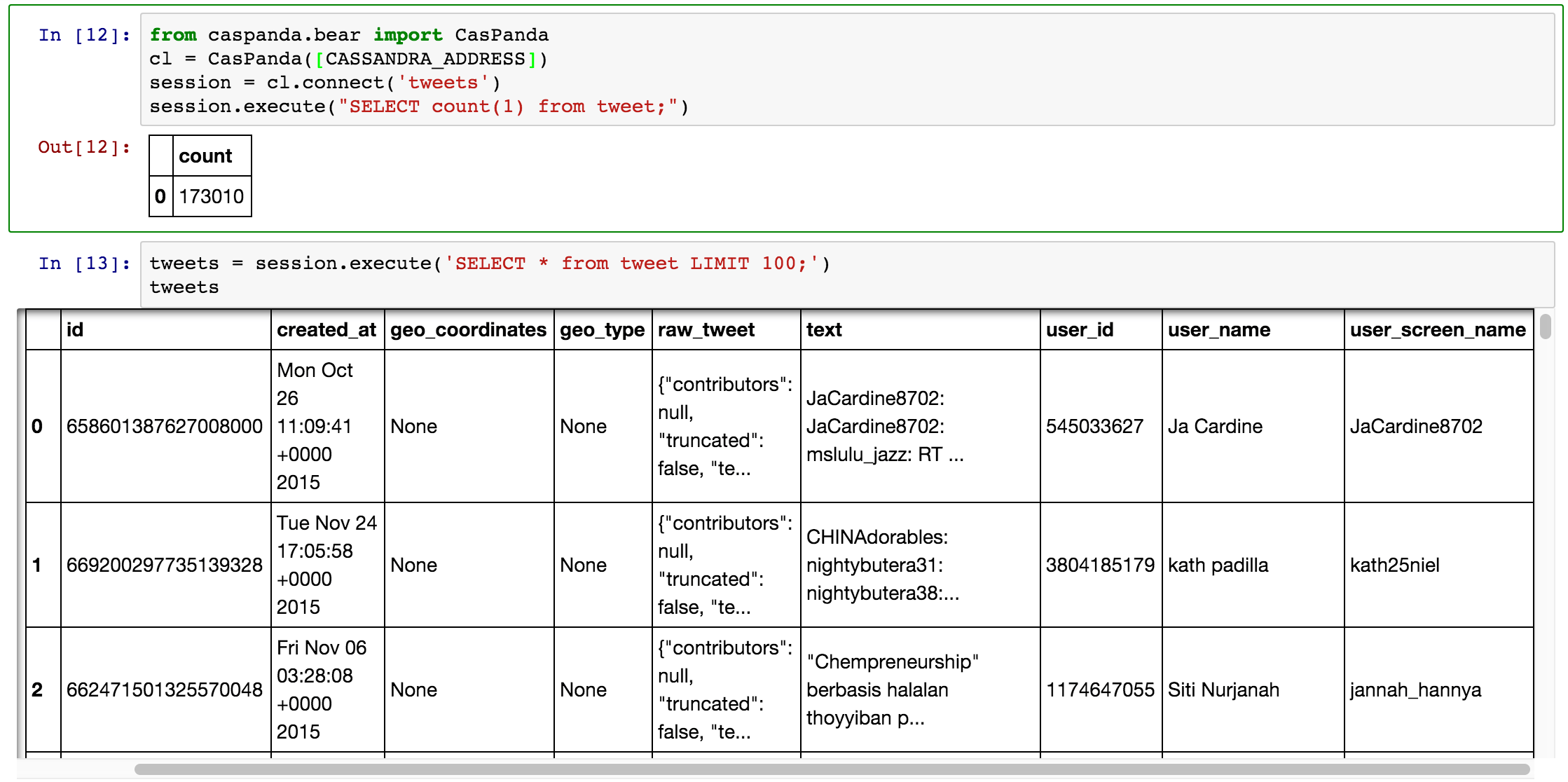
We query the Cassandra database directly using CQL, and the response gets loaded directly into a Pandas DataFrame. From there, we can filter, process, or make interesting visualizations.
Time for Data Analysis! Birds, Python, and now Pandas?
Now that we have the data stored up, it’s time to do something with it. We’ve already covered how much we like using iPython Notebooks with Pandas for exploring data. We were able to do the same in this case using the CasPanda library. We query the Cassandra database directly using CQL, and the response gets loaded directly into a Pandas DataFrame. From there, we can filter, process, or make interesting visualizations.
What did we learn?
Cassandra works as advertised, but it’s not a silver bullet for all your big data storage problems.
Overall, this was a very interesting experiment in setting up a highly scalable data ingestion pipeline for a potentially limitless data source. Cassandra works as advertised, but it’s not a silver bullet for all your big data storage problems.
- A lot of careful planning is required in setting up the database tables, depending on the types of queries to be done. It’s not quite a data lake where you throw absolutely everything in it and build schemas on the fly.
- Cost might also become an issue in the long term to make sure that each node has enough hardware resources to run. An m3.large instance on Amazon EC2 costs about USD140 per month.
- On the bright side, there are a lot of available tools written in Python for Cassandra integration and analysis. It’s also fairly easy to get up and running, thanks to the online documentation.
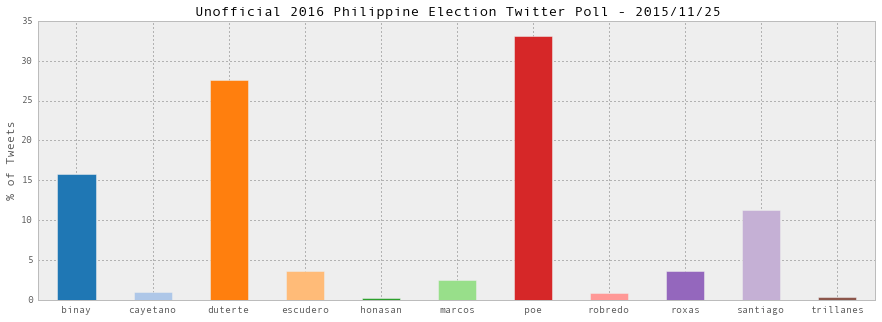
At the time of publishing, we’ve already collected and stored about 170,000 tweets related to the 2016 Philippine presidential and vice-presidential candidates to play around with. For starters, here’s our unofficial Twitter poll based on the number of tweets that mention the candidates as of today:
References:
- http://www.statisticbrain.com/twitter-statistics/
- https://wiki.apache.org/cassandra/CassandraHardware


