Automating Financial Document Analysis for the World Bank with a Document Intelligence AI Engine
The World Bank aims to better understand local government units’ (LGU) spending patterns and trends in budget execution over a period of four years by examining the LGU’s financial statements collected by Philippines Commission on Audit (COA). The use of this data would provide the World Bank task team an additional layer of granularity that has not been explored in the existing literature. In particular, the team will be able to track expenditure patterns by sectoral allocation and expense class and compare these against the programmed budget for that particular year.
Unfortunately, this information is stored across thousands of individual Word, PDF, or Excel files – preventing the World Bank’s team from carrying out such analyses.
- Because of the variety of formats and the inconsistencies in data structure, it would take an estimated 105 work days to turn the 5,033 files in the database into standardized spreadsheets suitable for analysis
- We built a system to automatically extract relevant information from unstructured data using DocumentAI.
- This pipeline fully processes each file in under a minute – a huge reduction in time spent compared to a manual process, granting time-savings and eliminating manual work for the World Bank Team
Though parsing documents may sound straightforward, a closer look at the data revealed inconsistencies that may pose challenges to a simple program, or to a manual encoder.
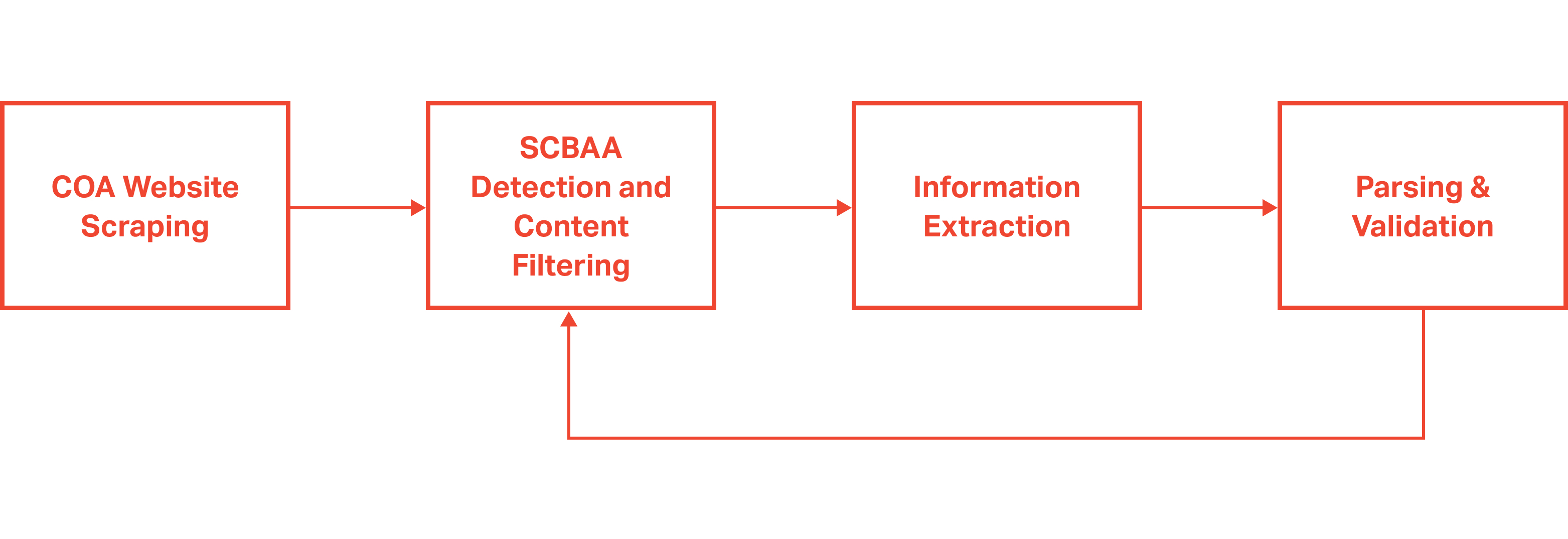
COA Website Data Extraction
Website Data Extraction
The financial statements were found on the Commission on Audit website, and stored in subfolders separated by year, region, province, and municipality or city. We first built a tool to extract the financial statements of over a thousand LGUs over the period of 2015-2018 by traversing the website and collecting links to documents within each folder. Then, we programmatically downloaded all the files in one go. All files reside in Google Cloud Storage for easy sharing and access.
SCBAA Detection and Content Filtering
Keyword Matching
Each LGU provides a Statement of Comparison of Budgeted and Actual Amounts (SCBAA), which contains a breakdown of the preliminary and final budget, as well as actual spending across sectors (e.g. Education, Social Services, etc.) and expense class (personnel services, maintenance and operating expenditures, and capital outlays).
With a complete set of files, we used keyword matching to identify which files contained the SCBAA, and pull out the relevant pages to be parsed. This addressed the issue of inconsistent file storage – eliminating the need to manually search for the SCBAA document, and reducing the processing time needed to parse irrelevant pages.
Information Extraction
Optical Character Recognition and Table Detection
Around 35% of the files were provided in PDF or Word Document formats – which could not directly transformed into tables. In addition, parsing the contents of the SCBAA document proved to be a challenge--a lot of LGUs used different formats in reporting fiscal data. To address this, we leveraged OCR tools such as Tesseract and Textract – to transform the documents into digital formats.
This was by no means a straightforward task. Although the tools helped us pull out a bulk of the information, additional image preprocessing was necessary to handle blurry images – which otherwise were not be read accurately by Textract. Collided rows – which are tables without its borders drawn in – can also be confusing, and a layer of keyword matching and data wrangling was necessary to identify which rows were meant to be together.
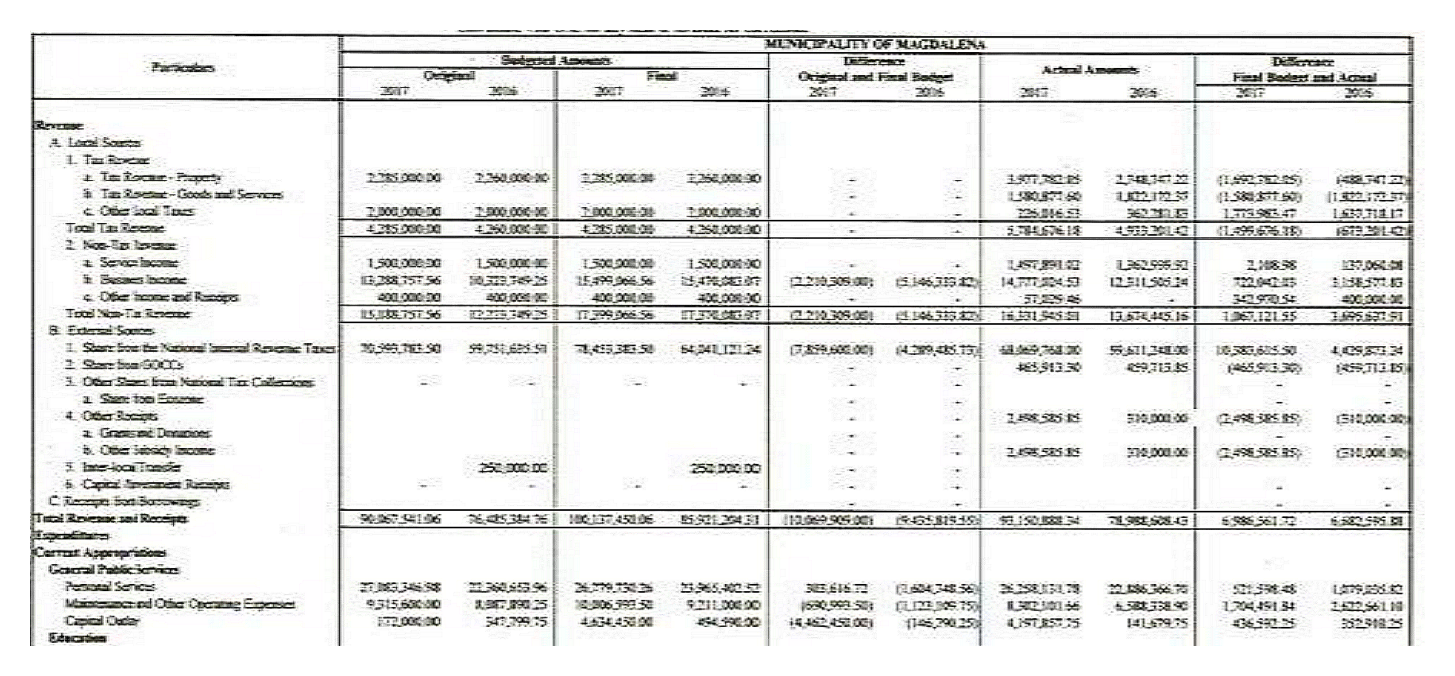
Example of a blurry image that underwent sharpening and contrast adjustment before OCR
Parsing and Validation
Keyword Matching, Data Wrangling, Fuzzy Match
Upon obtaining the files from the OCR stage of the pipeline, we parsed the files to identify relevant information – while further correcting the data to improve accuracy.
Multiple keywords mapped to the same category – whether these were typos, or different ways of specifying a category. To handle this, users fed in a document containing keywords and corresponding categories, which the system used to make the right classifications. We worked with domain experts from the World Bank to generate this document, which ultimately produced the final output. To validate these, we compared the keywords we’ve detected from the ones specified by the domain experts.
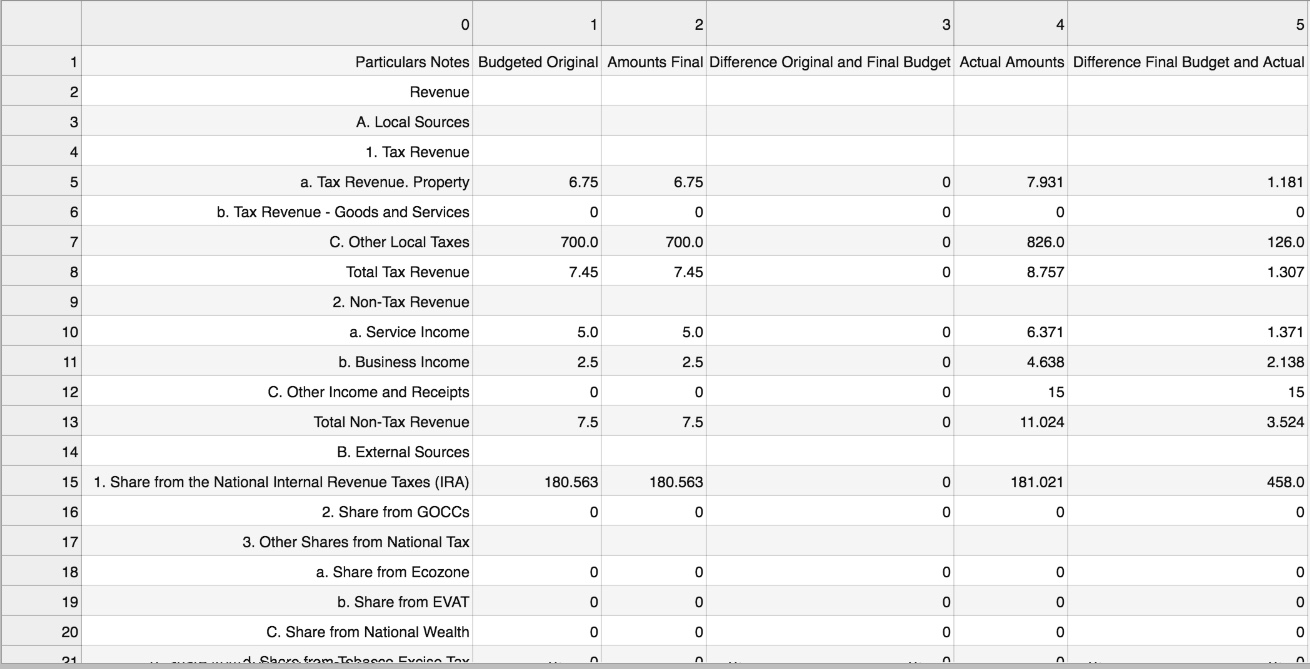
Example keywords that we used to parse the file
Hidden rows and columns also posed a challenge, as the multiple Excel versions made them difficult to identify consistently. Here, we implemented a series of checks on subtotals and differences – to ensure that the system only incorporated the correct figures.
Misclassified items added another layer of complexity to the task. To resolve this, we wrote business rules to allow the code to reclassify line items under their correct headings using the classifications. With the reclassified line items, the code could then aggregate relevant line items to generate the output.
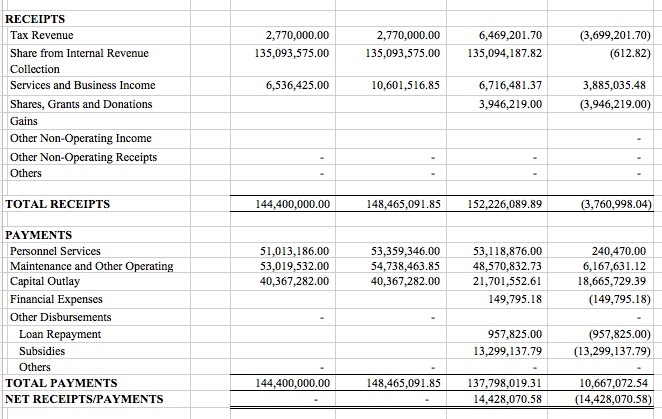
Validation
With all the methods used to handle different file types and formats, accounting where each file was in the pipeline became a complicated task in and of itself. To address this, we carefully logged each transformation in the pipeline, allowing us to trace and track the process of each document.
Our validation method also allowed us to generate progress summaries for weekly meetings, to help the World Bank understand how the system works.
The following tools were crucial to the success of the project
- Google Compute Engine: Provides an additional compute resource for our processing pipelines
- Google Cloud Storage: Cloud platform for storing extracted documents and processed files
- Tesseract: Open source optical character recognition tool used to extract textual information from PDFs
- Textract: Table detection software hosted on Amazon Web Services
The impact of the team’s work with the World Bank was two-fold. First, the team processed 5,033 files across four years over the course of three months with 30x speedup, providing the World Bank team with data which will produce insights on budget allocations, the distribution of expenditure, and the ability of LGUs to execute their budgets.
Second, the system provides a way to parse financial statements in the future, reducing the need for manual encoding, saving both time and effort in the process. Our DocumentAI solution was able to process a file end to end in under a minute – a reduction in time spent compared to a manual process.
Ultimately, the team’s work supports the larger push towards data transparency and better governance – and is a step towards better collection and maintenance of public data.