
What’s the story? How we taught a deep learning model to understand the topics in thousands of online articles
We worked with a major digital media company in Southeast Asia to build an artificial intelligence model that understands readers’ topics of interests based on the content they were consuming. We taught a deep learning model how to read an article then suggest related topics based on a nuanced understanding of how the content of the article relates to other concepts.
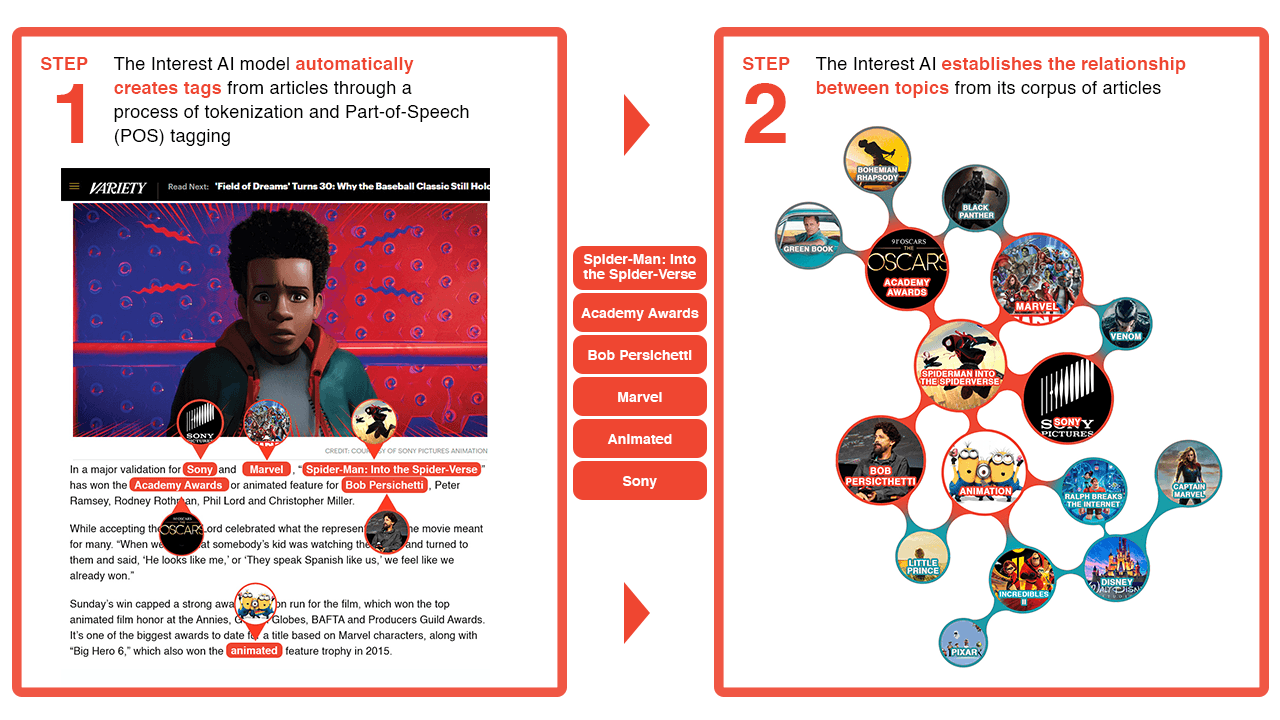
For example, an article about Spider-Man would be automatically linked to articles about Sony Entertainment, Iron Man, and animated films, all without human input. This improves on systems that are reliant on human readers tagging the content by being faster and more granular.
These insights can be used in a wide variety of ways, from automated content meta-tagging to hyper-personalized targeting based on individual users content consumption and search behavior.
Understanding Users’ Evolving Interests
To set the stage, our client publishes hundreds of pieces of content on a daily basis. As an organization reliant on advertising revenue, it is essential for them to understand the preferences of their readers. Up to this point, their understanding has been limited to big topic classes, like “sports”, “celebrity news”, and “basketball”, and they rely on their writers to manually meta-tag hundreds of articles each week with the correct topic categories. Our client wanted to improve its “related articles” recommendations to its readers by automating this process with higher levels of nuance.
In addition, they believe that better insights on reader interests leads to improved content quality and increased reader loyalty. By understanding the interest of individual readers over time, they will also be able to provide more targeted promotions through their advertising partners.
Our solution has two major components.
- We trained a word embeddings model to understand words and the semantic relationships between words by feeding it hundreds of thousands of news articles.
- We run each new piece of content through the model to pull out the key topics of that content, and relate them to other articles with similar key topics.
Building a Topic Network
Word of warning: the next few paragraphs can be quite technical here and there and may be skipped by the casual reader!
Building word representations using fastText
For those still reading at this point, here it becomes technical! We used the open source fastText library to build vector representations of our client’s digital content, a body of tens of thousands of online articles across a wide range of topics from hard news to sports and entertainment.
A. Text Corpus Pre-processing
We then subjected the tens of thousand of articles to a process of sentence parsing, tokenization, and Part-of-Speech (POS) tagging. As a last step, to keep only those words that represent a “topic”, we removed all tokens (unigrams) that are not a noun or adjective.
| Body Content |
‘When we think of Filipino breakfast, what’s usually in the minds of many is a platter of steamed rice, sunny-side
up egg, and tocino. Yet we forget that our seemingly harmless collective gastric imagination could divide a nation
of 103 million. Some 5.6% of it will not eat the tocino.</p>
<p>But somewhere in a Maguindanao town, 50-year-old Ronnie Mampen is turning the common Filipino <em>almusal </em>halal.
(.....)’
|
| English | Yes |
| Sentence Parsing |
[
‘When we think of Filipino breakfast, what’s usually in the minds of many is a platter of steamed rice, sunny-side
up egg, and tocino.’,
‘Yet we forget that our seemingly harmless collective gastric imagination could divide a nation of 103 million.’,
‘Some 5.6% of it will not eat the tocino.</p>
<p>’,
‘But somewhere in a Maguindanao town, 50-year-old Ronnie Mampen is turning the common Filipino <em>almusal </em>halal’
]
|
| Tokenization |
[‘When’, ‘we’, ‘think’, ‘of’, ‘Filipino’, ‘breakfast’, ‘,’, ‘what’,...,‘platter’, ‘of’, ‘steamed’, ‘rice’,...]
|
| POS Tagging |
[(‘When’,ADV), (‘we’,PRON), (‘think’,VERB), (‘of’,ADP), (‘Filipino’,PROPN), (‘breakfast’,NOUN), (‘,’,PUNCT),
(‘what’,NOUN) … (‘platter’,NOUN), (‘of’,ADP), (‘steamed’,ADJ), (‘rice’, NOUN)...]
|
| Filtering and Lemmatization |
[ ‘filipino’, ‘breakfast’, ‘what’, ‘mind’, ‘many’, ‘platter’, ‘steamed’, ‘rice’… ]
|
| Unigrams |
[ ‘filipino’, ‘breakfast’, ‘mind’, ‘many’, ‘platter’, ‘steamed’, ‘rice’… ]
|
Table 1. Sample Transformation
B. Phrase Modeling
Our next step was phrase modeling to automatically detect multi-word topics, extracting n consecutive words that tend to co-occur more frequently than expected by random chance. If n=2, these consecutive words are called bigrams, whereas if n>3, they are referred to as trigrams (as you might have guessed).
C. Vocabulary Building
In the third step, we filtered even more to eliminate 1) noisy words (tokens that include punctuations ([!\"$%&'()*+,./:;<=>?@[\]^`{|}~]) and start with numbers) and 2) frequency outliers (tokens that either appear in almost all of the documents or those that are rarely used). We excluded tokens that are not in at least 10 articles and those that appear in 50% of the articles. Whatever words were retained after these extensive pruning steps, were our topic vocabulary or the topics in our interest network.
D. fastText Training
To establish the relationship between topics, we used fastText to create vectorized word representations on the pre-processed text corpus. FastText is a word embedding framework that takes after the skip-gram architecture of word2vec. Word2vec predicts context words given the current word as input.
This way, the model learns the relationships between topics at scale without explicit human labeling.
A Visual Topic Network
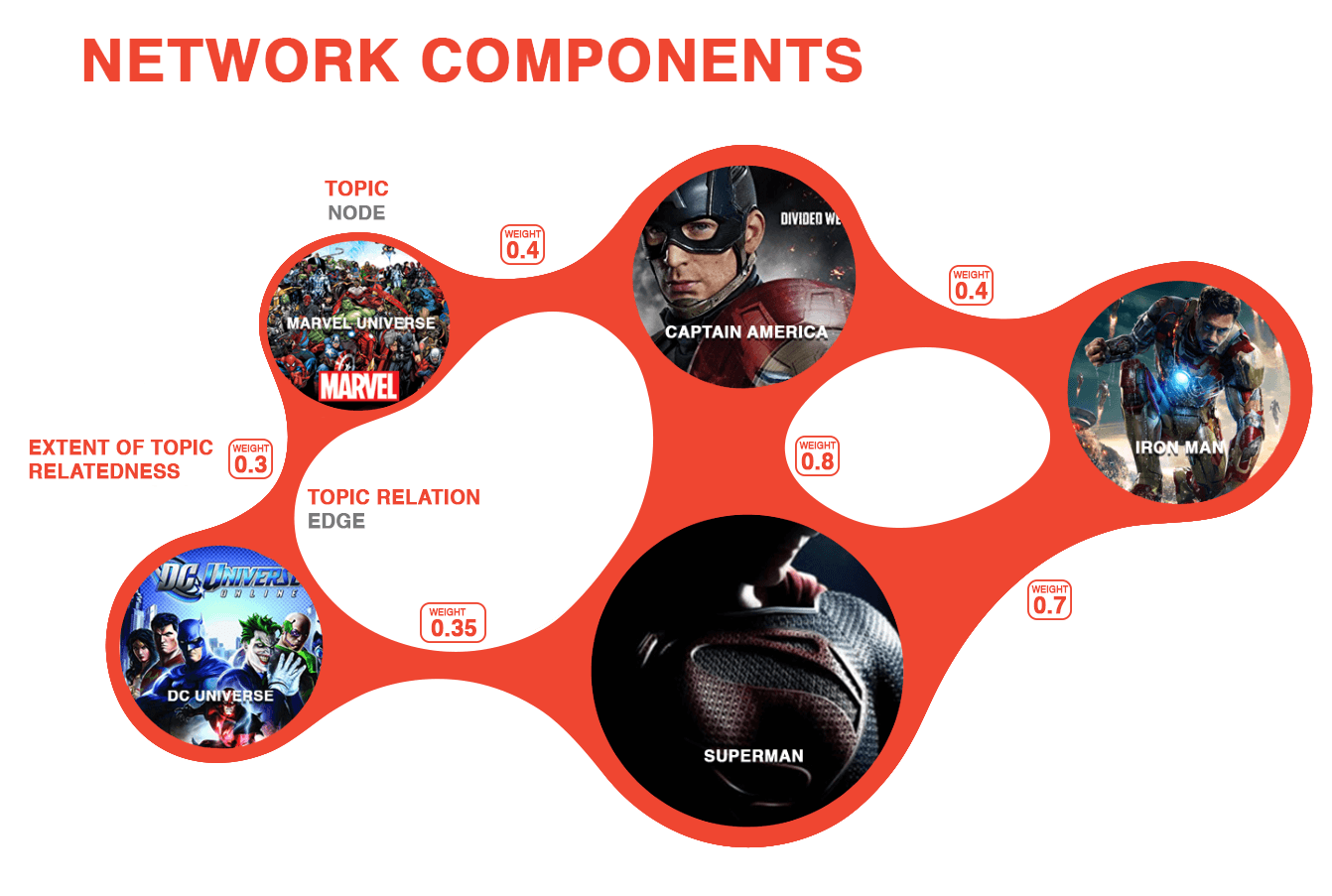
To get a better grasp of the relationships between these topics, we created a Topic Network.
A topic network is made up out of a set of nodes and a set of edges. Each node represents a topic, for example a person, place, thing, or idea. An edge is the connection between two nodes if the topics are sufficiently related (the technical term for this is “close in the vector space”).
A typical way to do this is by measuring the Cosine Similarity. For the casual reader, the main thing to remember about Cosine Similarity is that Cosine Similarity values range from 0 to 1. The closer the value is to 1, the more related the topics are. In this case we considered two topics to be related if their cosine similarity exceeds a threshold of 0.5.
A Subgraph of the Topic Network
Use Cases
While it takes human content taggers weeks to manually read and tag 10,000 articles, our model does the same task automatically in seconds. Our client can now fully automate putting topic tags (meta-tags) against new articles.
Hyper-personalized Targeting Based on Consumers’ Interests
Even more interesting then improving the process of tagging, is what we can do with it: more personalized targeting based on individual interests. We can capture consumer interest data in multiple ways; 1) through tools like Google Analytics 360, or 2) captured from users that are logged in to the service. We can track an individual consumer’s interest in certain topics over a period of time by mapping the tags of the articles the consumer opened against the nodes of the Topic Network.
Derive Interest from Searches
We can also use the system for Internet search data from individual users within a content platform (news web site, music portal, etc). We can match the search data from the user against the nodes of the Topic Network.
For example, when a user searches for “korean drama on netflix” , this search instance would be attached to the nodes of korean_drama and netflix. We can use the phrase models (bigrams and trigrams) trained on the tens of thousands of articles that are our corpus to detect phrases from any of the search terms.
We can then transform pre-processed searches using a bag of words representation (for those interested to learn more about bag of words and its application, here’s a link to the corresponding wikipedia article) to identify all terms that have an exact match in the vocabulary.
For all the terms that do not have a vocabulary match, we do a lookup in the fastText vector space. If we find sufficiently similar topics, we add their corresponding nodes to the list of topics that are already mapped to the search instance.
| Sample Search Instance | Pre-processed Search Instance | Mapped Nodes (Topics) |
|---|---|---|
‘korean drama on netflix’ |
korean, drama, netflix |
(korean_drama, 1.0), (netflix, 1.0) |
Table 2. Search Matching
| Sample Search Instance | Pre-processed Search Instance | Mapped Nodes (Topics) |
|---|---|---|
‘dispacito justin bieber’ |
dispacito, justin_bieber |
(justin_bieber, 1.0), (despacito, 0.82) |
Table 3. Search with Partial Match
Once mapped, we can carry out an analysis of search trends. For example, we can explore the popularity of topics in the network over time. We can detect topics that exhibit different trend behaviors. For instance, we can focus on topics that tend to peak and certain times of the year and investigate whether the peak is sustained for a long period or just a result of sudden bursts. More importantly, we can extract communities of users that have a certain level of affinity towards a topic.
We used a cloud-based architecture to run our models. Running AI models requires on and off need for massive computing power, so we choose Google Cloud Platform (GCP). For the word2vec model we ran an experiment using Google TensorFlow, but ultimately the FastText architecture was superior for our needs.
- Google Cloud Platform
- fastText
- TensorFlow
Contact Us
How can our team help you get insights from data? Leave us a note on social media or email us directly at [email protected].


